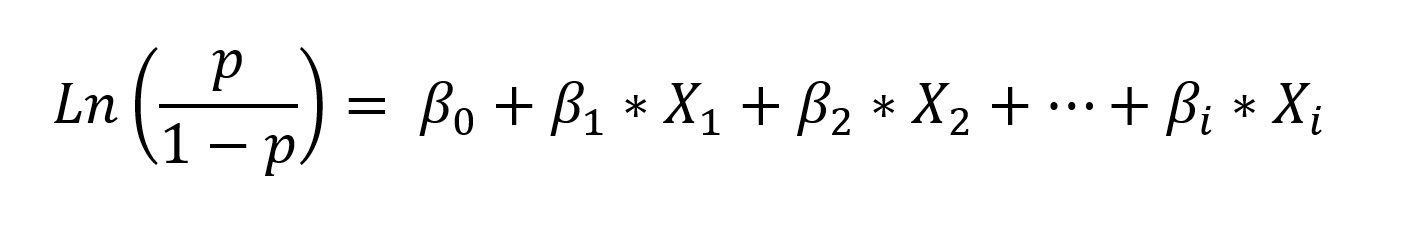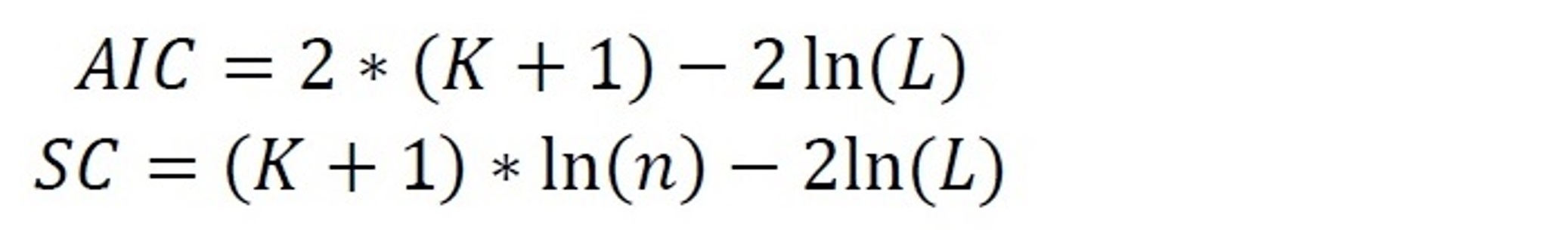Pour vouloir comprendre notre tambouille, vous devez être soit courageux soit irresponsables. Dans les deux cas, vous aimez souffrir. Nous, on les bichonne nos masos. Alors vous allez en avoir pour votre argent. Comment ça, vous n’avez pas payé ? Mince, il faut remédier à ça...
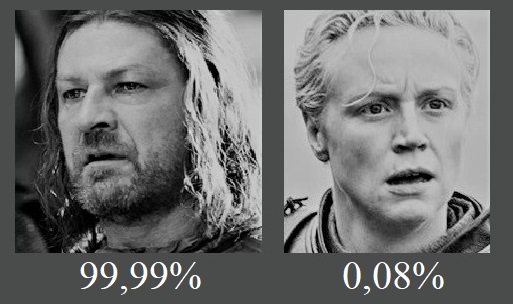
Prenons un exemple concret (il n’y en aura pas beaucoup). 38% des personnages féminins décèdent au cours de la série contre 52% des personnages masculins. « Chouette ! se dit Catelyn proba décès : 91%. J’ai moins de risque de mourir que mon mari proba décès : 100%. » Quand tout à coup patatra. Elle meurt (Fig. 1).
Alors déjà, si 38% c’est mieux que 52%, ce n’est pas la joie pour autant. D'autant plus que ces risques globaux cachent bien des choses ! Les personnages féminins et masculins diffèrent en de nombreux points. Par exemple : les personnages masculins sont plus souvent des combattants et leurs homologues féminins se prostituent plus. Or, un combattant a plus de risque de mourir qu’un non-combattant (logique, non ?) et un personnage qui se prostitue à moins de risque de mourir qu’un autre qui ne se prostitue pas ! (voir les statistiques descriptives). Dès lors, comment savoir si les personnages féminins meurent moins parce qu’ils sont féminins (on parle alors d’effet propre du sexe sur la mortalité) ou si ce sont leurs caractéristiques particulières qui les protègent (on parle d’effet de composition : par exemple, si les prostitué.e.s meurent moins et que les personnages féminins se prostituent plus, alors les personnages féminins sont protégés par cet effet de composition).
Pour neutraliser les effets de composition, nous recourons aux régressions. Celles-ci nous permettent de déterminer l’effet propre du sexe sur les risques de mortalité, toutes choses égales par ailleurs. Concrètement, on peut alors étudier l’impact du sexe sur la mortalité en faisant comme si les personnages féminins et masculins combattaient et se prostituaient autant. Génial, non ?
Bref, on met toutes les caractéristiques qu’on veut dans le modèle. On n’oublie pas de dire au modèle si le personnage est mort ou non dans la série, sinon il galère... À partir de ça, le modèle peut calculer le risque théorique de mourir d’un personnage compte tenu de ses caractéristiques. Pas mal, non ? Vous pouvez jeter un œil à ces risques de décéder en cliquant ici !
Les résultats des régressions peuvent être utiles pour faire des prédictions : vous disposez de risques calculés sur les sept premières saisons et vous les appliquez à la prochaine saison. C’est un peu osé parce que les scénaristes peuvent faire ce qu’ils veulent dans l’ultime saison. Jon Snow proba décès : 2% peut donc (re)mourir puisque l'intrigue n'aura plus besoin de lui. On peut aussi s’en servir pour démontrer des causalités : par exemple, Catelyn Stark est morte parce qu’elle était un grand seigneur et Oberyn Martell proba décès : 100%parce qu’il combattait. Encore une fois, c’est osé. Ils sont surtout morts parce que les scénaristes l’ont décidé. Nous utilisons simplement les régressions pour observer des liens entre le risque de mourir et certaines caractéristiques : il existe ainsi un lien entre le fait de combattre et celui de mourir !
Pour ceux qui ne se sentent pas encore très à l'aise avec la lecture des régressions (on peut comprendre), nous proposons un exemple complet de lecture ici. Pour d'autres exemples concrets, n’hésitez pas à vous reporter aux régressions présentées dans les articles (« GoT : série féministe ou misogyne ? », « GoT : des corps « masculins et normaux » ? »...) qui sont toujours accompagnées de notes de lecture. C’est normalement compréhensible.
Ça y est. Vous en savez assez pour lire les articles proposés. Toutefois voici pour les curieux (ou les masos) quelques détails supplémentaires pour comprendre les dossiers universitaires.
Avec p la probabilité de mourir au cours de la série, X
i
les variables dépendantes, B
i
les coefficients de régression calculés.
- Si ce coefficient est négatif : la caractéristique protège de la mort.
- Si ce coefficient est positif : la caractéristique expose à la mort.
Toutefois, nous n’utilisons pas ces coefficients dans nos articles. En effet, il est très difficile d’interpréter ce coefficient et d’en faire des phrases concrètes. Dommage, la formule est assez esthétique !
) entre les caractéristiques et les risques de décès ». Pour cela elle dispose d’une vraie liste de personnages morts ou non. Elle va faire en sorte que ceux qui sont morts aient effectivement un « score » plus élevé que ceux qui sont vivants. Une fois que les B
i
sont déterminés (il s’agit pour ceux qui sont copains-copains avec les mathématiques d’un problème de maximisation), p est une fonction des X
i
».
Oui, mais pourquoi cette mocheté de logarithme népérien ? Simplement pour que le score (p) soit compris entre 0 et 1 et soit associable à une probabilité !
Quoiqu'il en soit, nous préférons dans nos articles l’utilisation des Odds Ratios (OR).
- Si l’OR est plus petit que 1, la caractéristique protège de la mort.
- Si l’OR est plus grand que 1, la caractéristique expose à la mort.
Mais quel est l’intérêt par rapport aux coefficients ? L’interprétation ! Si l’OR est de 2 pour le fait de combattre on peut alors dire que « par rapport à un personnage qui ne combat pas, un personnage qui combat a deux fois plus de risque de mourir plutôt que de ne pas mourir ». Si l’OR est de 0,5 pour la prostitution : « par rapport à un personnage qui ne se prostitue pas, un personnage qui se prostitue a deux fois moins (1/0,5=2) de risque de mourir plutôt que de ne pas mourir ».
La significativité statistique d’un coefficient permet d’évaluer le niveau de certitude selon lequel on peut affirmer qu’il existe un lien entre la caractéristique et le risque de décéder. Par exemple, pour une significativité de 5% : « il existe un risque de 5% pour que la sous ou la surmortalité mise au jour soit en fait inexistante ».
En sciences humaines et sociales, nous prenons en général 5% de risque au maximum. Au-delà, le risque de se planter est trop grand : le résultat est dit « non significatif ». Mais ce n’est qu’une convention et ça dépend de l’objectif ! Imaginez : vous avez une conjonctivite. Un nouveau médicament fait des merveilles. Seulement, il cause la mort dans 4% des cas. Vous prenez le risque ? En sciences humaines et sociales, 4% de risque c’est peu. En médecine, ça peut être dramatique...
Nous aimons tellement le risque que nous vous l'indiquons même jusqu’à 10% (°) ! Les lecteurs se souviendront donc qu’il faut prendre ces résultats avec des pincettes.
Notre modèle est créé ! Il reste à en évaluer la qualité. Nous n’en parlons pas dans nos articles. On vous demande un acte de foi. Vous pouvez toutefois, retrouver des discussions sur la qualité des modèles ici.
Nous pouvons distinguer deux types d’indicateurs :
Type 1: Les indicateurs qui comparent les risques calculés par le modèle à la réalité
Une première manière d’évaluer la qualité du modèle est de compter le nombre de paires concordantes. D’accord, mais qu’est-ce que c’est ?
L'ordinateur trie nos personnages en deux groupes : ceux qui sont morts et ceux, plus chanceux, qui ne le sont pas. Il va ensuite créer des paires en prenant à chaque fois un personnage mort et un vivant. Il compare ensuite les risques de décéder (calculés par le modèle) de la paire :
- Si le risque de mourir calculé par le modèle est plus fort pour le personnage effectivement mort que pour celui qui est en vie, c’est bien ! Cela veut dire que le modèle a marché : c’est une paire concordante.
- Sinon, c’est une paire discordante. Le modèle n’explique pas le fait qu’un personnage soit mort dans la série et l’autre non.
Nous avons 193 personnages vivants et 205 morts. Nous avons donc 39.565 paires à vérifier (205*193) ! Plus la part des paires concordantes dans le nombre total de paires est élevée, plus le modèle est explicatif.
Vous n'avez pas bien compris ? Pour plus d'explications sur les paires concordantes cliquez ici.
Attention ça se corse.
Voilà un autre indicateur de qualité du modèle (nommé c). Il s’agit de l’aire sous la courbe de ROC (proposée par Hosmer et Lemeshow en 1941) qui varie en 0 et 1. Alors, autant on peut expliquer concrètement ce que c’est qu’une paire concordante, autant là... on ne peut pas. Toujours est-il que l’on considère que la discrimination des deux populations (ici les personnages décédés et les personnages vivants) est :
- nulle si l’aire sous la courbe vaut moins de 50% ;
- acceptable si elle appartient à [70% ; 80%[ ;
- excellente si elle appartient à [80% ; 90%[ ;
- exceptionnelle si elle est supérieure ou égale à 90%.
Concrètement, le modèle comprend exceptionnellement bien ce qui différencie personnages vivants et personnages morts si l’indicateur est supérieur ou égal à 90%.
Type 2 : Les indicateurs s’appuyant sur la vraisemblance du modèle
La part de paires concordantes est cependant influencée par le nombre de variables introduites dans le modèle : plus j’injecte de variables dans mon modèle, plus celui-ci sera jugé « bon » par les indicateurs vus ci-dessus (paire concordante et aire sous la courbe de ROC). C’est assez facile à comprendre : n’importe quelle caractéristique peut expliquer une infime partie d’un phénomène. Vraiment n'importe quelle caractéristique ! Même la couleur de la voiture de l'acteur... C'est du hasard, mais il n'empêche que ça ne peut qu'améliorer l'indicateur des paires concordantes ! Alors comment pallier ce biais ?
Deux autres indicateurs nous renseignent sur la qualité du modèle tout en prenant en compte le nombre de variables introduites : le critère d’Alsaïke (AIC) et celui de Schwartz (SC) qui valent respectivement :
Avec L, la valeur maximale de la vraisemblance (calculée avec les valeurs estimées des paramètres) et K le nombre de variables introduites dans le modèle.
Plus ces critères sont petits, meilleure est la vraisemblance. Mais attention ! Si l’on ajoute une caractéristique supplémentaire, hop, les critères augmentent. Il faut donc vérifier, lorsque l’on ajoute une variable, que le gain en vraisemblance compense l’ajout de la variable : idéalement le critère doit diminuer. On peut se contenter d’une stagnation ou d’une légère augmentation si dans le même temps les paires concordantes et autres indicateurs augmentent fortement.
Vous l’aurez compris : tout est question d’équilibre. Il faut mettre assez de variables pour expliquer au mieux un phénomène tout en restant parcimonieux pour ne pas perdre en vraisemblance.
Pour interpréter ces deux critères, il est utile de connaître leur valeur pour un modèle sans caractéristique explicative (L
0
). Si nos indicateurs deviennent supérieurs à ce modèle qui par définition n’explique rien... on a du souci à se faire.
Utilisations des régressions logistiques dans le domaine de la recherche
Dans nos articles, et dans ceux d'autres études, nous étudions les éventuels liens purs existants entre les caractéristiques individuelles et la mort. Nous montrons par exemple que si les personnages féminins décèdent moins fréquemment que les personnages masculins c'est parce qu'elles sont moins souvent combattantes et plus souvent prostituées. On montre à l'aide des régressions logistiques qu'il n'existe probablement pas de lien pur entre le sexe et le risque de décéder et ce en neutralisant les effets de composition que sont la structure guerrière et le fait d'être ou non un.e prositué.e.
Les thématiques d'application des régressions logistiques n'ont aucune limite. Demandez à Romane qui en utilise à la pelle avec son équipe dans son travail (quel travail peut bien nécessiter le recours aux régressions logistiques ? Pour le savoir cliquez ici) ! Dans le monde de la recherche, on s'en sert également souvent pour mesurer des effet purs. Quelques exemples :
La taille du réseau familial a-t-il un effet pur sur la probabilité de déclarer avoir vécu des périodes difficiles pendant l'enfance en neutralisant les éventuels effets de composition de génération, de lieu de naissance,... : Golaz, V. et Lelièvre, E. (2012) « L'entourage familial pendant l'enfance et l'adolescence, entre faits et perceptions. Une analyse rétrospective des parcours de vie des Franciliens des générations 1930-1950 ». In : Population, (Vol. 67), p. 491-515. DOI 10.3917/popu.1203.0491. [En ligne] : https://www.cairn.info/revue-population-2012-3-page-491.htm [Consulté le 11 décembre 2018]
Pris un à un (indépendemment les uns des autres), les éléments suivants ont-ils un lien avec la probabilité d'avoir un troisième enfant : niveau de diplôme des parents, le sexe des deux premiers enfants, la vie conjugale des parents, la CSP...? : Breton, D. et Prioux, F. (2005) « Deux ou trois enfants ? Influence de la politique familiale et de quelques facteurs sociodémographiques ». In : Population, (Vol. 60), p. 489-522. DOI : 10.3917/popu.504.0489. [En ligne] : https://www.cairn.info/revue-population-2005-4-page-489.htm [Consulté le 11 décembre 2018]
L'« apparence ethnique » (mais aussi l’âge, le sexe, la manière de s’habiller) ont-ils un lien pur sur la probabilité d'être sujet à un contrôle d'identité ? : Jobard, F. Lévy, R. Lamberth, J. et al. (2012) « Mesurer les discriminations selon l'apparence : une analyse des contrôles d'identité à Paris ». In : Population, (Vol. 67), p. 423-451. DOI : 10.3917/popu.1203.0423. [En ligne] : https://www.cairn.info/revue-population-2012-3-page-423.htm [Consulté le 11 décembre 2018]
Utilisations des régressions logistiques sur le sujet de Game of Thrones
Pour voir d'autres études qui ont mené des regressions logistiques sur le sujet de Game of Thrones, cliquez ici.